
Generations from Get3DHuman rendered using Blender. We export generated shapes and visualize them in Blender. Besides generating 3D textured human models from random codes, our method also supports re-texturing a given shape (bottom left), shape and texture interpolation (bottom middle), and inversion from a given reference image (bottom right).
Abstract
Fast generation of high-quality 3D digital humans is important to a vast number of applications ranging from entertainment to professional concerns. Recent advances in differentiable rendering have enabled the training of 3D generative models without requiring 3D ground truths. However, the quality of the generated 3D humans still has much room to improve in terms of both fidelity and diversity. In this paper, we present Get3DHuman, a novel 3D human framework that can significantly boost the realism and diversity of the generated outcomes by only using a limited budget of 3D ground-truth data. Our key observation is that the 3D generator can profit from human-related priors learned through 2D human generators and 3D reconstructors. Specifically, we bridge the latent space of Get3DHuman with that of StyleGAN-Human via a specially-designed prior network, where the input latent code is mapped to the shape and texture feature volumes spanned by the pixel-aligned 3D reconstructor The outcomes of the prior network are then leveraged as the supervisory signals for the main generator network. To ensure effective training, we further propose three tailored losses applied to the generated feature volumes and the intermediate feature maps. Extensive experiments demonstrate that Get3DHuman greatly outperforms the other state-of-the-art approaches and can support a wide range of applications including shape interpolation, shape re-texturing, and single-view reconstruction through latent inversion.
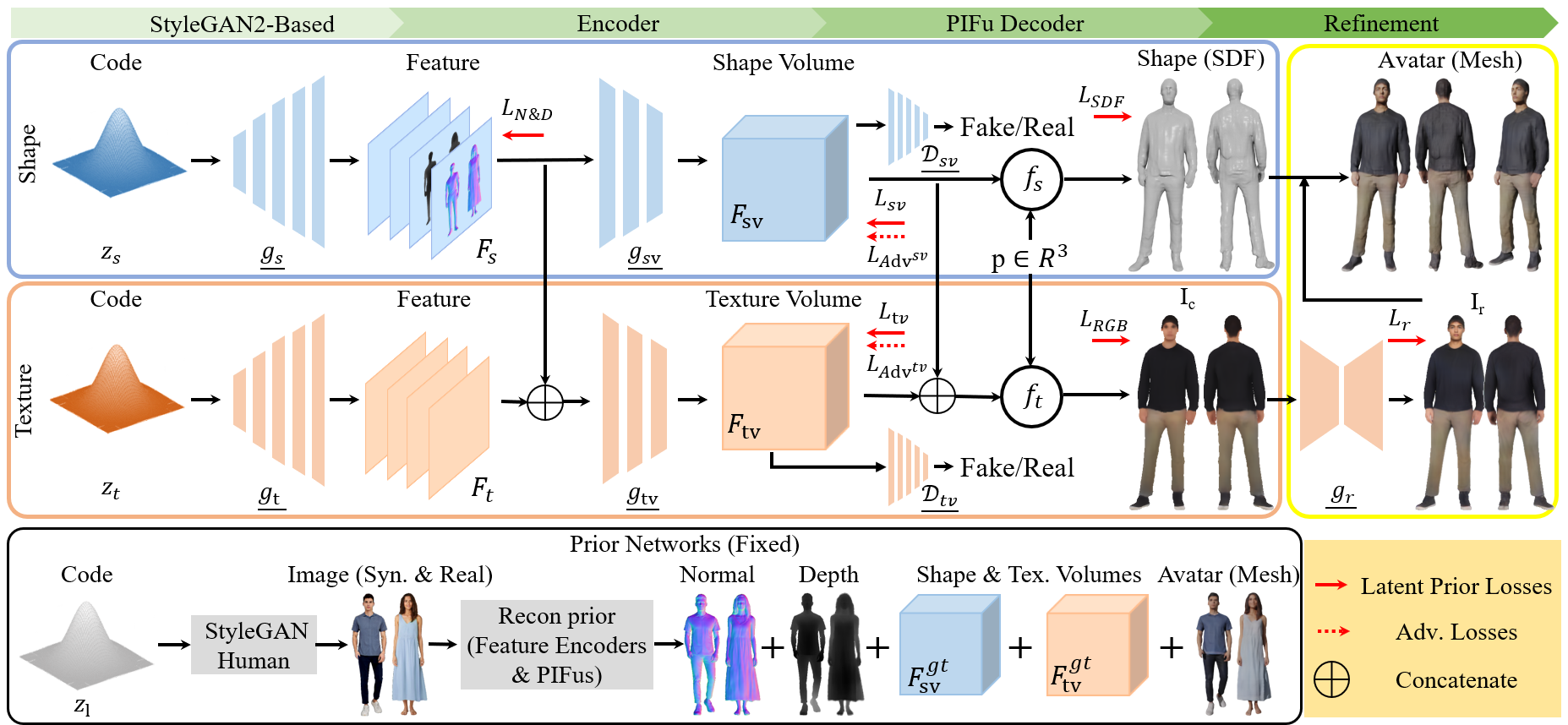
Overview of our framework. Our Get3DHuman consists of a shape generator (blue) and a texture generator (orange) with a refinement module (yellow) that enables nonexistent 3D human creation. Shape generator responds for generating a high-quality full-body geometry from a shape code and sends shape features to the texture generator. Texture generator predicts RGB colors of all points in the 3D space from a texture code and intermediate shape features. Trainable modules are underlined, including gs, gsv, Dsv, gt, gtv, Dtv, and gr. These seven modules are all trained from scratch. The prior networks (black) only produces supervisory signals for the training of form.

Interpolation examples
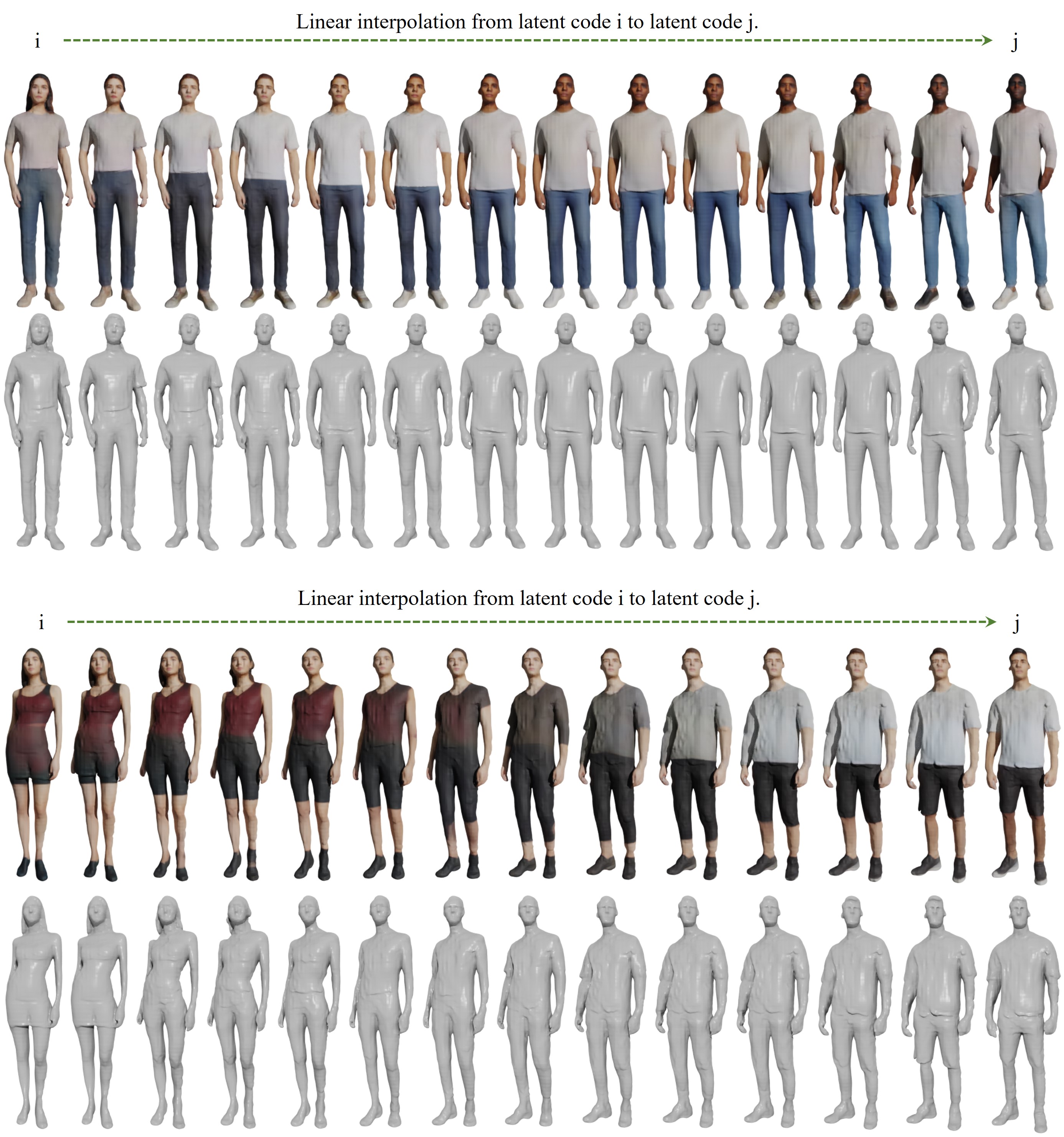
We randomly sample two sets of shape/texture latent codes to generate the right-/left- most examples, then interpolate both the shape and texture latent codes to generate the in-between examples.
Re-texturing examples

Visualization of re-texturing the fixed geometry by different texture latent codes. We can see different textures are diverse, plausible, and suitable for the given shape since our texture branch is conditioned on shape branch features.
Inversion results

In 2D GAN, inversion refers to find the corresponding latent code that generates a given target (image). Similarly, we are also searching suitable latent zs, zt for given feature volumes Fsv, Ftv.
Ablation study

Ablation study on adversarial losses and prior losses. We compare the human models generated from ''Adv. only'', ''Prior only'', and ''Ours Adv. + Prior''. Ours (Adv. & Prior) produces the best results with plausible details on both the shape and the appearance. The refinement module further improves the appearance.
Refinement module

Ablation on refinement module. Ablation on the refine module. Using the refinement module brings realistic texture details (bottom). "Image" are directly generated from the Pytorch, "Avatar" are rendered from texture models by using Blender.
Rendering methods

In this work, we mainly visualize the results by rendering textured meshes in Blender with lighting (left). Meanwhile, Get3DHuman can also render images via PyTorch without lighting (right).
BibTeX
@article{xiong2023Get3DHuman ,
author = {Zhangyang Xiong and Di Kang and Derong Jin and Weikai Chen and Linchao Bao and Shuguang Cui and Xiaoguang Han},
title = {Get3DHuman: Lifting StyleGAN-Human into a 3D Generative Model using Pixel-aligned Reconstruction Priors},
booktitle={ICCV},
year = {2023},
}